Teil 6: Grünland im Blick – Die Grünlandtemperatursumme (GTS) berechnen und anzeigen
Hallo und herzlich willkommen zum sechsten und vorerst letzten Teil unserer Kernserie zur Flutter Wetter-App!
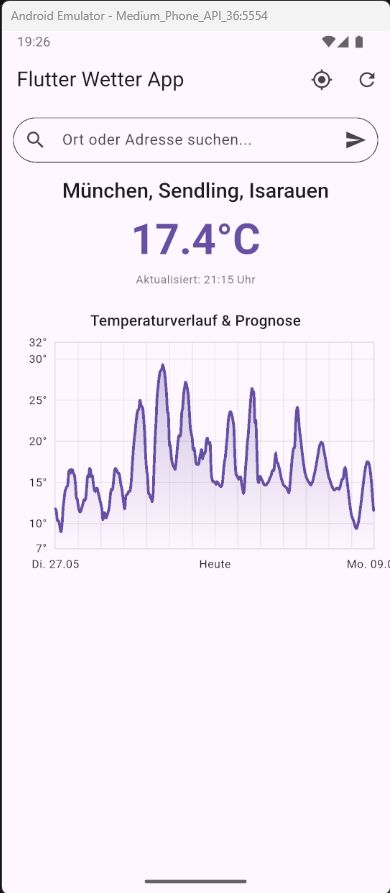
In den vorherigen Teilen haben wir eine Menge geschafft: von der Anzeige der aktuellen Temperatur über die Adresssuche bis hin zur Visualisierung des Temperaturverlaufs als Diagramm. Unsere App wird immer nützlicher!
Heute krönen wir das Ganze mit einer Spezialfunktion: der Berechnung und Anzeige der Grünlandtemperatursumme (GTS). Dieser agrarmeteorologische Wert ist besonders für Landwirte und Gärtner interessant, da er Aufschluss über den Vegetationsbeginn im Frühjahr gibt. Aber auch für Naturinteressierte ist es eine spannende Ergänzung.
Das Ziel für heute:
- Wir verstehen, was die Grünlandtemperatursumme ist und wie sie berechnet wird.
- Wir lernen, wie man historische Wetterdaten von einem anderen Endpunkt der Open-Meteo API (der Archiv-API) abruft.
- Wir implementieren die Berechnungslogik für die GTS, inklusive der Monatsfaktoren.
- Wir integrieren einen Caching-Mechanismus, um nicht bei jedem App-Start die gesamten historischen Daten neu laden zu müssen.
- Wir erstellen ein neues Widget, um die GTS ansprechend darzustellen.
Warum GTS?
Die GTS ist ein gutes Beispiel dafür, wie man mit Flutter und externen APIs auch spezifischere, fachliche Anforderungen umsetzen kann. Es erfordert Datenabruf, Datenverarbeitung und eine klare Logik.
Schritt 1: Den Code für Teil 6 holen
Wie immer findest du den Code für diesen Teil im Git-Repository.
- Öffne ein Terminal in deinem Projektordner (
flutter_weather_app_blog). - Sichere lokale Änderungen, falls vorhanden.
- Wechsle zum
main-Branch und aktualisiere:git checkout main
git pull origin main - Checke den Code-Stand für Teil 6 aus: (Tag-Name ggf. anpassen)
git checkout part6-gts-calculation - Abhängigkeiten holen & Code generieren:
flutter pub getdart run build_runner build --delete-conflicting-outputs
Öffne das Projekt in VS Code.
Schritt 2: Was ist die Grünlandtemperatursumme (GTS)?
Die GTS ist die Summe der positiven Tagesmitteltemperaturen (oberhalb von 0°C), die ab Jahresbeginn anfallen. Dabei werden die Werte im Januar mit dem Faktor 0,5 und im Februar mit 0,75 gewichtet. Ab März zählt jeder positive Tagesmittelwert voll (Faktor 1,0). Ein bestimmter Schwellenwert der GTS (oft um 200 °Cd – Grad Celsius Tage) signalisiert den nachhaltigen Beginn der Vegetationsperiode.
Berechnung: GTS = Σ (Tagesmittel – 0°C) * Monatsfaktor (Nur für Tage mit Tagesmittel > 0°C)
Schritt 3: Die Datenquelle – Open-Meteo Archiv-API
Um die GTS zu berechnen, benötigen wir die täglichen Durchschnittstemperaturen seit dem 1. Januar des aktuellen Jahres. Die normale Forecast-API von Open-Meteo liefert historische Daten nur für einen begrenzten Zeitraum (z.B. die letzten 7-90 Tage). Für längere historische Zeitreihen bietet Open-Meteo eine separate Archiv-API.
- Neue API-Endpunkte (
lib/src/core/constants/app_constants.dart):- Wir haben Konstanten für die Basis-URL und den Endpunkt der Archiv-API hinzugefügt:
static const String openMeteoArchiveApiBaseUrl = 'archive-api.open-meteo.com';
static const String openMeteoArchiveEndpoint = '/v1/archive';
- Wir haben Konstanten für die Basis-URL und den Endpunkt der Archiv-API hinzugefügt:
- Parameter für GTS (
lib/src/core/constants/app_constants.dart):- Ebenfalls neu sind die Konstanten für die GTS-Berechnung selbst:
static const double gtsBaseTemperature = 0.0;
static const Map<int, double> gtsMonthlyFactors = {1: 0.5, 2: 0.75};
static const int gtsLocationCachePrecision = 2; // Für Caching
- Ebenfalls neu sind die Konstanten für die GTS-Berechnung selbst:
Schritt 4: Datenmodelle für historische Daten (data Layer Models)
Die Archiv-API liefert tägliche Daten in einer ähnlichen, aber doch eigenen Struktur. Daher brauchen wir neue Modelle:
lib/src/features/weather/data/models/daily_units_model.dart(NEU): Analog zumHourlyUnitsModel, aber für tägliche Daten (z.B. Einheit fürtemperature_2m_mean).lib/src/features/weather/data/models/daily_data_model.dart(NEU): Bildet dasdaily-Objekt der Archiv-API ab. Enthält Listen fürtime(Datum-Strings) undtemperature_2m_mean(tägliche Durchschnittstemperaturen). DiefromJson-Methode parst diese inDateTime– unddouble-Listen.lib/src/features/weather/data/models/historical_response_model.dart(NEU): Das Gesamtmodell für die Antwort der Archiv-API, analog zumForecastResponseModel.
Schritt 5: API-Service erweitern (data Layer Datasource)
Der WeatherApiService (lib/src/features/weather/data/datasources/weather_api_service.dart) wurde um eine Methode zum Abruf der historischen Daten erweitert:
getHistoricalDailyTemperatures(NEUE Methode):- Nimmt
latitude,longitude,startDateundendDateals Parameter. - Baut die URL für den Archiv-API-Endpunkt (aus
AppConstants). - Fordert
daily=temperature_2m_meanan. - Parst die JSON-Antwort mithilfe des neuen
HistoricalResponseModel. - Enthält robustes Error-Handling, ähnlich wie
getForecastWeather.
- Nimmt
Schritt 6: Der GTS-Berechnungsservice (application Layer)
Die eigentliche Logik zur Berechnung der GTS und das Caching der dafür benötigten Daten haben wir in einen neuen Service ausgelagert:
lib/src/features/weather/application/gts_calculator_service.dart(NEU):- Riverpod Provider: Wird über
@riverpodbereitgestellt (gtsCalculatorServiceProvider) und bekommt denWeatherApiServiceinjiziert. - Caching: Implementiert einen einfachen In-Memory-Cache (
_historicalDataCache,_forecastForGtsCache)._getLocationCacheKey: Erstellt einen eindeutigen Schlüssel für den Cache basierend auf gerundeten Koordinaten (um Ungenauigkeiten durch GPS zu minimieren).- Vor einem API-Aufruf wird geprüft, ob gültige Daten im Cache vorhanden sind (
_cacheDuration).
calculateGtsForLocation(LocationInfo location)Methode:- Cache-Prüfung: Versucht, historische Tagesmittelwerte aus dem Cache zu laden.
- API-Abruf (historisch): Wenn nicht im Cache, ruft es
_apiService.getHistoricalDailyTemperaturesauf, um die Tagesmittelwerte vom 1. Januar bis gestern zu holen. Speichert das Ergebnis im Cache. - Datenaufbereitung: Die erhaltenen Daten werden in einer
Map<DateTime, double>(Datum -> Temperatur) gespeichert. - Forecast-Ergänzung (Lücke füllen): Die Archiv-API liefert oft Daten nur bis zum Vortag. Wenn die letzten Tage des aktuellen Jahres fehlen, um bis „gestern“ zu kommen (z.B. weil die Archivdaten noch nicht aktualisiert sind), versucht der Service, diese Lücke mit stündlichen Daten aus der Forecast-API zu füllen.
- Dafür wird
_apiService.getForecastWeathermitpast_days(um die Lücke abzudecken) undforecast_days: 0aufgerufen. - Aus den stündlichen Forecast-Daten werden dann Tagesmittelwerte für die fehlenden Tage berechnet und zu den
dailyAverageshinzugefügt. Auch diese Forecast-Daten werden gecacht.
- Dafür wird
- GTS-Summation: Iteriert durch alle Tage des aktuellen Jahres (bis gestern) in der
dailyAverages-Map.- Wenn die Tagesmitteltemperatur >
gtsBaseTemperature(0°C) ist: - Der entsprechende
gtsMonthlyFactor(Jan: 0.5, Feb: 0.75, sonst 1.0) wird angewendet. - Der Beitrag des Tages
(Tagesmittel - Basis) * Faktorwird zur Gesamtsumme addiert.
- Wenn die Tagesmitteltemperatur >
- Gibt die berechnete
gtsSumzurück.
- Fehlerbehandlung: Wirft
GtsCalculationExceptionbei Problemen.
- Riverpod Provider: Wird über
Schritt 7: Datenmodell und Repository anpassen (domain & data Layer)
WeatherDataEntität (lib/src/features/weather/domain/entities/weather_data.dart):- Wurde um das Feld
final double greenlandTemperatureSum;erweitert. - Die
emptyundcopyWithMethoden wurden angepasst.
- Wurde um das Feld
WeatherRepositoryImpl(lib/src/features/weather/data/repositories/weather_repository_impl.dart):- Abhängigkeit: Bekommt jetzt den
GtsCalculatorServiceüber den Konstruktor injiziert (dank Riverpod). getWeatherForLocation-Methode:- Startet den Aufruf von
_apiService.getForecastWeather()(für aktuelle und stündliche Daten) und_gtsCalculatorService.calculateGtsForLocation()parallel mitFutures. - Wartet mit
awaitauf beide Ergebnisse. - Fängt Fehler von
calculateGtsForLocationab und gibt in diesem Falldouble.nanfür die GTS zurück, damit der Rest der Wetterdaten trotzdem angezeigt werden kann. - Fügt den erhaltenen
gtsValuebeim Erstellen desWeatherData-Objekts hinzu. - Kann jetzt auch
GtsCalculationExceptionfangen und inGtsFailureumwandeln.
- Startet den Aufruf von
- Abhängigkeit: Bekommt jetzt den
Schritt 8: Anzeige der GTS (presentation Layer)
lib/src/features/weather/presentation/widgets/gts_display.dart(NEU):- Ein neues
StatelessWidget, das dengtsValueals Parameter erhält. - Stellt die GTS in einer
Cardansprechend dar, inklusive Icon und Einheit (°Cd). - Zeigt „–“ an, wenn der
gtsValuedouble.nanist (also ein Fehler bei der Berechnung auftrat).
- Ein neues
lib/src/features/weather/presentation/screens/weather_screen.dart:- In der
_buildSuccessContent-Methode wird nun das neueGtsDisplay-Widget hinzugefügt und bekommtdata.greenlandTemperatureSumübergeben. Es wird zwischen der aktuellen Temperaturanzeige und dem Diagramm platziert.
- In der
Schritt 9: Änderungen am State Management (application Layer)
Überraschenderweise sind hier keine Änderungen im WeatherState oder WeatherNotifier direkt nötig!
- Der
WeatherStateverwendet bereits dasWeatherData-Objekt, das nun dasgreenlandTemperatureSum-Feld enthält. - Der
WeatherNotifierruft dasWeatherRepositoryauf, das nun einWeatherData-Objekt mit befüllter GTS zurückliefert. Der Notifier reicht dieses Objekt einfach an den State weiter.
Das ist ein weiterer Beleg für die Vorteile einer guten Entkopplung: Die UI und der State-Notifier müssen die Details der GTS-Berechnung nicht kennen.
Schritt 10: Ausführen und Testen!
Starte die App (F5):
- Lade das Wetter für einen Ort (GPS oder Suche).
- Unter der aktuellen Temperatur und vor dem Diagramm sollte nun eine neue Karte mit der Grünlandtemperatursumme erscheinen.
- Beobachte die Logs: Du solltest sehen, wie der
GtsCalculatorServicearbeitet, historische und ggf. Forecast-Daten für die Ergänzung abruft. Beim zweiten Laden für denselben Ort (innerhalb der Cache-Dauer) sollten die Daten schneller aus dem Cache kommen. - Vergleich (optional): Wenn du Zugang zu offiziellen GTS-Werten für deinen Ort hast, kannst du versuchen, die Ergebnisse zu vergleichen. Beachte, dass es leichte Abweichungen geben kann, je nach genauer Datenquelle und Methodik der offiziellen Stellen.
Fazit und Abschluss der Kernserie
Herzlichen Glückwunsch! Du hast die Grünlandtemperatursumme erfolgreich in deine Wetter-App integriert. Damit haben wir alle Kernfunktionen umgesetzt, die wir uns am Anfang vorgenommen hatten.
In diesem Teil hast du gelernt:
- Wie man Daten von einem anderen API-Endpunkt (Archiv-API) abruft.
- Wie man historische Daten verarbeitet.
- Wie man eine spezifische fachliche Berechnung (GTS mit Monatsfaktoren) implementiert.
- Wie man einen einfachen In-Memory-Cache erstellt und nutzt, um API-Anfragen zu reduzieren.
- Wie man Daten aus verschiedenen Quellen (historisch, Forecast) kombiniert, um ein vollständiges Bild zu erhalten.
- Wie eine gut strukturierte App das Hinzufügen komplexer Logik erleichtert, ohne dass alle Teile der App angepasst werden müssen.
Unsere Wetter-App ist nun ein ziemlich umfassendes Projekt, das viele Aspekte der Flutter-Entwicklung abdeckt. Du hast eine solide Grundlage geschaffen, auf der du aufbauen und weitere Ideen umsetzen kannst!
Wie geht es weiter?
Das war das Ende der geplanten Kernfunktionen. Aber eine App ist selten „fertig“. Mögliche nächste Schritte könnten sein:
- UI-Verfeinerungen: Icons für Wetterbedingungen, schönere Übergänge, Anpassung an verschiedene Bildschirmgrößen.
- Weitere Wetterdaten: Windgeschwindigkeit, Luftfeuchtigkeit, Sonnenaufgang/-untergang.
- Einstellungen: Wahl der Temperatureinheit (Celsius/Fahrenheit), Anpassung der Diagramm-Optik.
- Caching verbessern: Persistenter Cache (z.B. mit
shared_preferencesoder einer lokalen Datenbank). - Testing vertiefen: Mehr Unit-, Widget- und Integration-Tests schreiben.
- Fehler-Reporting: Integration eines Dienstes wie Sentry oder Firebase Crashlytics.
- Deployment: Die App für den Google Play Store vorbereiten und veröffentlichen.
Ich hoffe, diese Serie hat dir Spaß gemacht und dir geholfen, Flutter und die App-Entwicklung besser zu verstehen. Nutze das Gelernte als Sprungbrett für deine eigenen Projekte!
Vielen Dank fürs Mitmachen und viel Erfolg bei deinen zukünftigen Flutter-Abenteuern!
Weiterführende Ressourcen & Vertiefung
- Open-Meteo Archiv API:
- Dokumentation: https://open-meteo.com/en/docs/historical-weather-api – Details zu den verfügbaren Parametern und Daten der Archiv-API.
- Grünlandtemperatursumme (GTS):
- Agrarmeteorologische Informationen: Suche nach „Grünlandtemperatursumme Erklärung“ oder „GTS Landwirtschaft“, um mehr über die Bedeutung und Berechnungsmethoden zu erfahren (z.B. von Wetterdiensten oder landwirtschaftlichen Portalen).
- Caching-Strategien in Flutter:
- Einfaches In-Memory Caching: Wie wir es implementiert haben, ist ein guter Start.
shared_preferences: https://pub.dev/packages/shared_preferences – Für das Speichern einfacher Schlüssel-Wert-Paare (kleine Datenmengen, die auch nach App-Neustart erhalten bleiben).- Lokale Datenbanken (z.B.
sqflite): https://pub.dev/packages/sqflite – Für komplexere, strukturierte Daten, die persistent gespeichert werden sollen.
- Parallele Ausführung mit
Future:- Dart Dokumentation (Concurrency): https://dart.dev/language/concurrency – Erklärt
Futures und wie man asynchrone Operationen handhabt. Future.wait: https://api.dart.dev/stable/dart-async/Future/wait.html – Nützlich, wenn man auf mehrere Futures warten muss, bevor man fortfährt (wir haben sie hier sequentiell nach dem Starten awaited, aberFuture.waitist eine Alternative für bestimmte Szenarien).
- Dart Dokumentation (Concurrency): https://dart.dev/language/concurrency – Erklärt